This page gives you an overview of every OCR model in NLU which are provided by Spark OCR.
Additionally you can refer to the OCR tutorial Notebooks
Overview of all OCR features
Overview of OCR Text Extractors
These models grab the text directly from your input file and returns it as a Pandas DataFrame
| NLU Spell | Transformer Class |
|---|---|
nlp.load(img2text) |
ImageToText |
nlp.load(pdf2text) |
PdfToText |
nlp.load(doc2text) |
DocToText |
Overview of OCR Table Extractors
These models grab all Table data from the files detected and return a list of Pandas DataFrames,
containing Pandas DataFrame for every table detected
| NLU Spell | Transformer Class |
|---|---|
nlp.load(pdf2table) |
PdfToTextTable |
nlp.load(ppt2table) |
PptToTextTable |
nlp.load(doc2table) |
DocToTextTable |
File Path handling for OCR Models
When your nlu pipeline contains a ocr spell the predict method will accept the following inputs :
- a
stringpointing to a folder or to a file - a
list,numpy arrayorPandas Seriescontaining paths pointing to folders or files - a
Pandas DataframeorSpark Dataframecontaining a column namedpathwhich has one path entry per row pointing to folders or files
For every path in the input passed to the predict() method, nlu will distinguish between two cases:
- If the path points to a
file, nlu will apply OCR transformers to it, if the file type is processable with the currently loaded OCR pipeline. - If the path points to a
folder, nlu will recursively search for files in the folder and sub-folders which have file types which are applicable with the loaded OCR pipeline.
NLU checks the file endings to determine whether the OCR models can be applied or not, i.e. .pdf, .img etc..
If your files lack these endings, NLU will not process them.
Image to Text
Sample image:

nlu.load('img2text').predict('path/to/haiku.png')
Output of IMG OCR:
| text |
|---|
| “The Old Pond” by Matsuo Basho |
| An old silent pond |
| A frog jumps into the pond— |
| Splash! Silence again. |
PDF to Text
Sample PDF:

nlu.load('pdf2text').predict('path/to/haiku.pdf')
Output of PDF OCR:
| text |
|---|
| “Lighting One Candle” by Yosa Buson |
| The light of a candle |
| Is transferred to another candle— |
| Spring twilight |
DOCX to text
Sample DOCX:
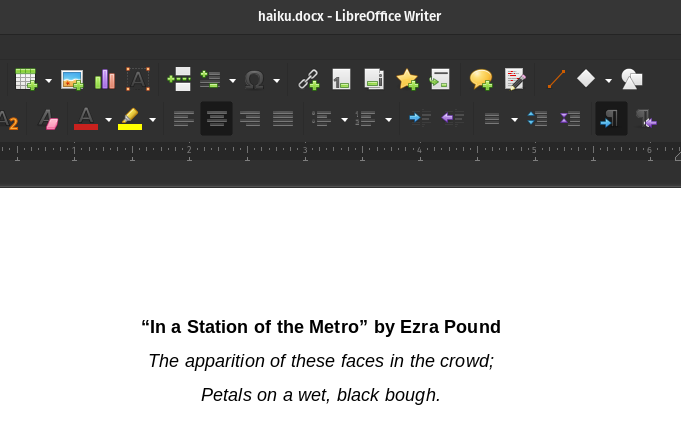
nlu.load('doc2text').predict('path/to/haiku.docx')
Output of DOCX OCR:
| text |
|---|
| “In a Station of the Metro” by Ezra Pound |
| The apparition of these faces in the crowd; |
| Petals on a wet, black bough. |
PDF with Tables
Sample PDF: 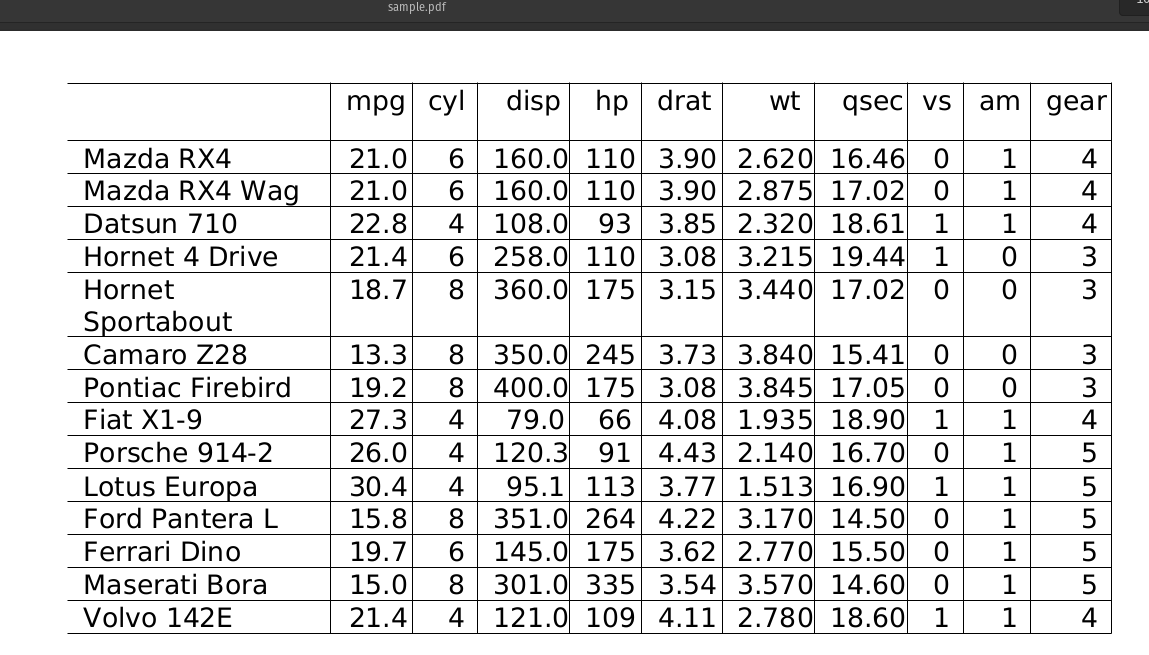
nlu.load('pdf2table').predict('/path/to/sample.pdf')
Output of PDF Table OCR :
| mpg | cyl | disp | hp | drat | wt | qsec | vs | am | gear |
|---|---|---|---|---|---|---|---|---|---|
| 21 | 6 | 160 | 110 | 3.9 | 2.62 | 16.46 | 0 | 1 | 4 |
| 21 | 6 | 160 | 110 | 3.9 | 2.875 | 17.02 | 0 | 1 | 4 |
| 22.8 | 4 | 108 | 93 | 3.85 | 2.32 | 18.61 | 1 | 1 | 4 |
| 21.4 | 6 | 258 | 110 | 3.08 | 3.215 | 19.44 | 1 | 0 | 3 |
| 18.7 | 8 | 360 | 175 | 3.15 | 3.44 | 17.02 | 0 | 0 | 3 |
| 13.3 | 8 | 350 | 245 | 3.73 | 3.84 | 15.41 | 0 | 0 | 3 |
| 19.2 | 8 | 400 | 175 | 3.08 | 3.845 | 17.05 | 0 | 0 | 3 |
| 27.3 | 4 | 79 | 66 | 4.08 | 1.935 | 18.9 | 1 | 1 | 4 |
| 26 | 4 | 120.3 | 91 | 4.43 | 2.14 | 16.7 | 0 | 1 | 5 |
| 30.4 | 4 | 95.1 | 113 | 3.77 | 1.513 | 16.9 | 1 | 1 | 5 |
| 15.8 | 8 | 351 | 264 | 4.22 | 3.17 | 14.5 | 0 | 1 | 5 |
| 19.7 | 6 | 145 | 175 | 3.62 | 2.77 | 15.5 | 0 | 1 | 5 |
| 15 | 8 | 301 | 335 | 3.54 | 3.57 | 14.6 | 0 | 1 | 5 |
| 21.4 | 4 | 121 | 109 | 4.11 | 2.78 | 18.6 | 1 | 1 | 4 |
DOCX with Tables
Sample DOCX: 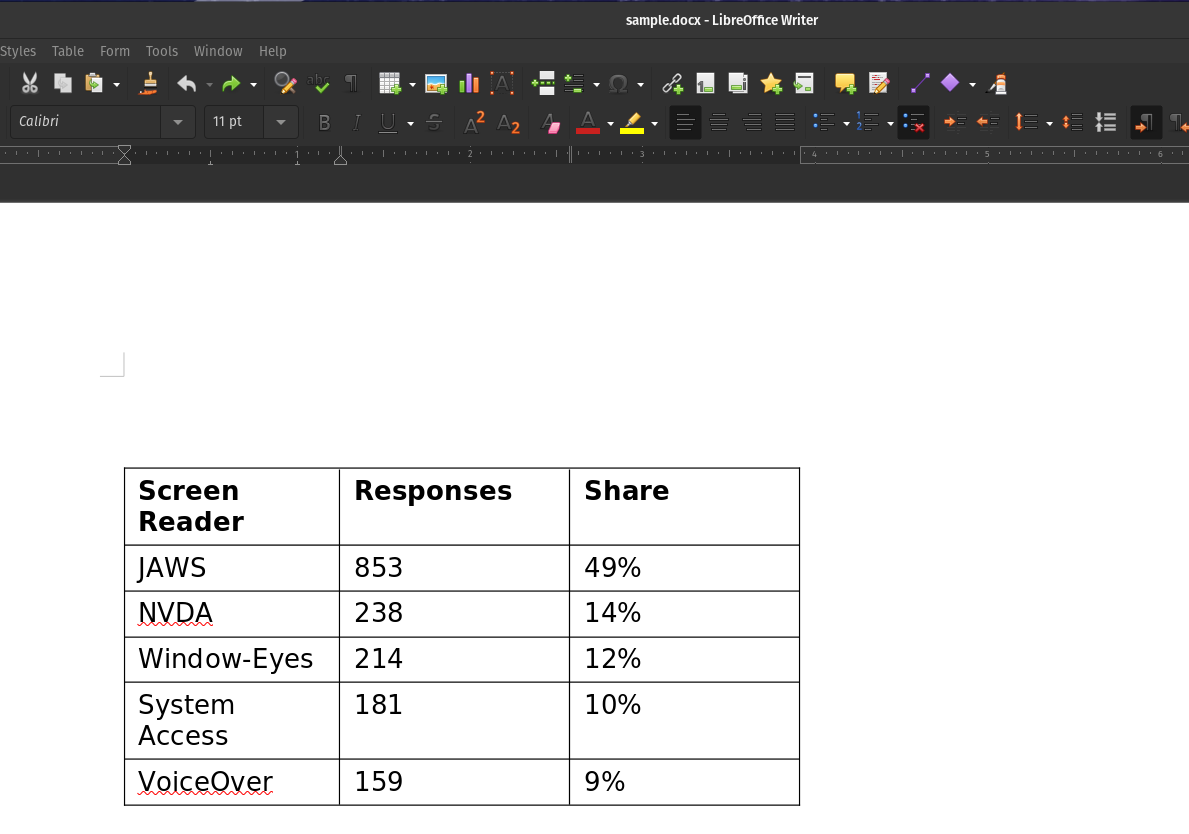
nlu.load('doc2table').predict('/path/to/sample.docx')
Output of DOCX Table OCR :
| Screen Reader | Responses | Share |
|---|---|---|
| JAWS | 853 | 49% |
| NVDA | 238 | 14% |
| Window-Eyes | 214 | 12% |
| System Access | 181 | 10% |
| VoiceOver | 159 | 9% |
PPT with Tables
Sample PPT with two tables: 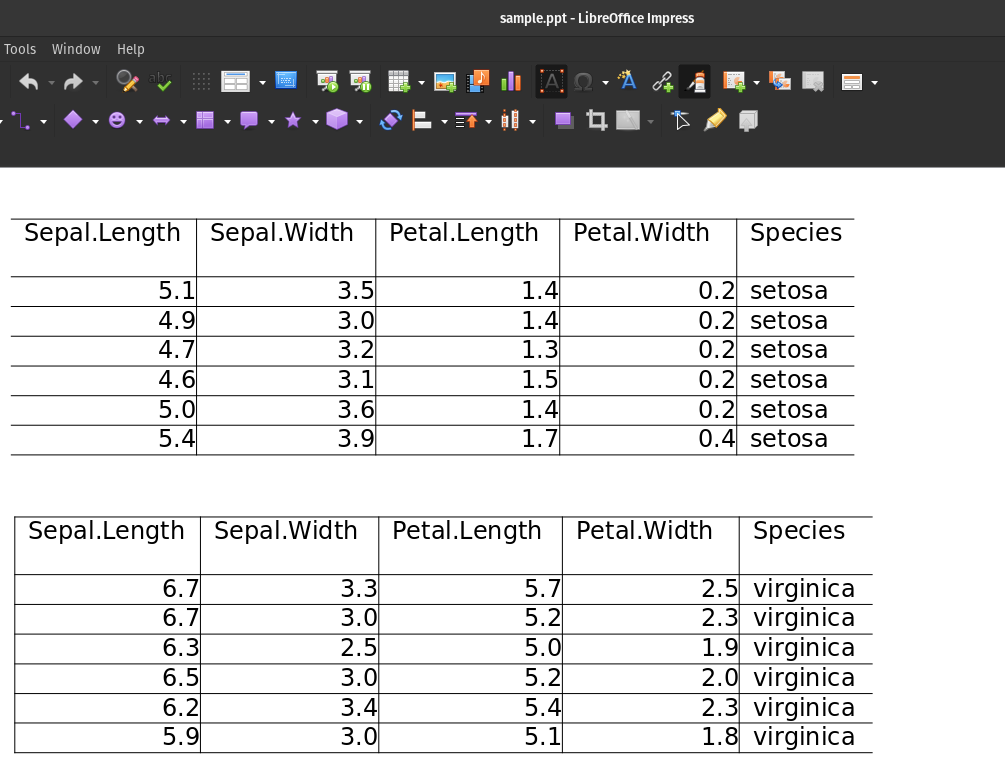
nlu.load('ppt2table').predict('/path/to/sample.docx')
Output of PPT Table OCR :
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 4.9 | 3 | 1.4 | 0.2 | setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5 | 3.6 | 1.4 | 0.2 | setosa |
| 5.4 | 3.9 | 1.7 | 0.4 | setosa |
and
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species |
|---|---|---|---|---|
| 6.7 | 3.3 | 5.7 | 2.5 | virginica |
| 6.7 | 3 | 5.2 | 2.3 | virginica |
| 6.3 | 2.5 | 5 | 1.9 | virginica |
| 6.5 | 3 | 5.2 | 2 | virginica |
| 6.2 | 3.4 | 5.4 | 2.3 | virginica |
| 5.9 | 3 | 5.1 | 1.8 | virginica |
Combine OCR and NLP models
Sample image containing named entities from U.S. Presidents Wikipedia:

nlu.load('img2text ner').predict('path/to/presidents.png')
Output of image OCR and NER NLP :
| entities_ner | entities_ner_class | entities_ner_confidence |
|---|---|---|
| Four | CARDINAL | 0.9986 |
| Abraham Lincoln | PERSON | 0.705514 |
| John F. Kennedy), | PERSON | 0.966533 |
| one | CARDINAL | 0.9457 |
| Richard Nixon, | PERSON | 0.71895 |
| John Tyler | PERSON | 0.9929 |
| first | ORDINAL | 0.9811 |
| The Twenty-fifth Amendment | LAW | 0.548033 |
| Constitution | LAW | 0.9762 |
| Tyler’s | CARDINAL | 0.5329 |
| 1967 | DATE | 0.8926 |
| Richard Nixon | PERSON | 0.99515 |
| first | ORDINAL | 0.9588 |
| Gerald Ford | PERSON | 0.996 |
| Spiro Agnew’s | PERSON | 0.99165 |
| 1973 | DATE | 0.9438 |
| Ford | PERSON | 0.8337 |
| second | ORDINAL | 0.9119 |
| Nelson Rockefeller | PERSON | 0.98615 |
| 1967 | DATE | 0.589 |
Authorize NLU for OCR
You need a set of credentials to access the licensed OCR features. You can grab one here
Authorize anywhere via providing via JSON file
If you provide a JSON file with credentials, nlu will check whether there are only OCR or also Healthcare secrets.
If both are contained in the JSON file, nlu will give you access to healthcare and OCR features, if only one of them
is present you will be accordingly only authorized for one set of the features.
You can specify the location of your secrets.json like this :
path = '/path/to/secrets.json'
nlu.auth(path).load('licensed_model').predict(data)
Authorize via providing String parameters
You can manually enter your secrets and authorize nlu for OCR and Healthcare features
import nlu
AWS_ACCESS_KEY_ID = 'YOUR_SECRETS'
AWS_SECRET_ACCESS_KEY = 'cgsHeZR+YOUR_SECRETS'
OCR_SECRET = 'YOUR_SECRETS'
JSL_SECRET = 'YOUR_SECRETS'
OCR_LICENSE = "YOUR_SECRETS"
SPARK_NLP_LICENSE = 'YOUR_SECRETS'
# this will automatically install the OCR library and NLP Healthcare library when credentials are provided
nlu.auth(SPARK_NLP_LICENSE,AWS_ACCESS_KEY_ID,AWS_SECRET_ACCESS_KEY,JSL_SECRET, OCR_LICENSE, OCR_SECRET)